Offline & Slashing Risks: Are Self-Cover Options Enough?

Introduction
Previously, Lido purchased slashing insurance from Unslashed Finance. Lido stopped purchasing cover through Unslashed and voted in favor of exploring self-cover. This post aims to set stage in terms of outlining the landscape of cover options and possible developments.
We outline the typical risk scenarios (now, after Altair hardfork, and in the hypothetical future), the amounts of slashings and penalties, and evaluate their impact to understand whether Lido could self-cover the losses.
Based on the analysis performed, we find that the most realistic impact is low enough for self-cover to be a viable option, but not low enough to be completely trivial. Additionally, we find that risk can be significantly reduced by non-financial actions, such as promoting validator diversity and operator distribution, as well as putting in place mechanisms to maintain high validation quality standards.
Offline & Slashing Penalty Overview
This section refers to the penalty types, methods to calculate them and could be skipped. To simplify the explanation all formulae presented have been transformed in order to give a general idea of penalty types and sizes. The risk modelling and assessment of analytical results in the other sections were done using the actual methods from the specs.
Currently, performing validator duties includes proposing blocks and creating attestations. The Altair spec introduces one more duty: participation in the sync committee that is responsible for signing each block of the canonical chain.
While block proposals and the sync committee participations happen infrequently, as there is only one proposer per slot and one sync committee consisting of 512 validators per 256 epochs, attestations should be done once per epoch. Failing to perform these duties properly leads to be penalized and, in case of slashable actions, being forcefully ejected from the Beacon Chain.
Here and further we use 'Phase 0' and 'Altair' as monikers for corresponding Ethereum Proof-of-Stake Consensus Specifications (Phase 0, Altair).
Offline Validator
A validator being offline misses a block if it was chosen as a proposer, does not participate in attestation and (Altair only) the sync committee.
Being offline brings 2 penalties (note that there is no penalty for not proposing a block):
- For missing source-, target-, and head- vote (FFG penalty) during each epoch of being offline.
- Phase 0
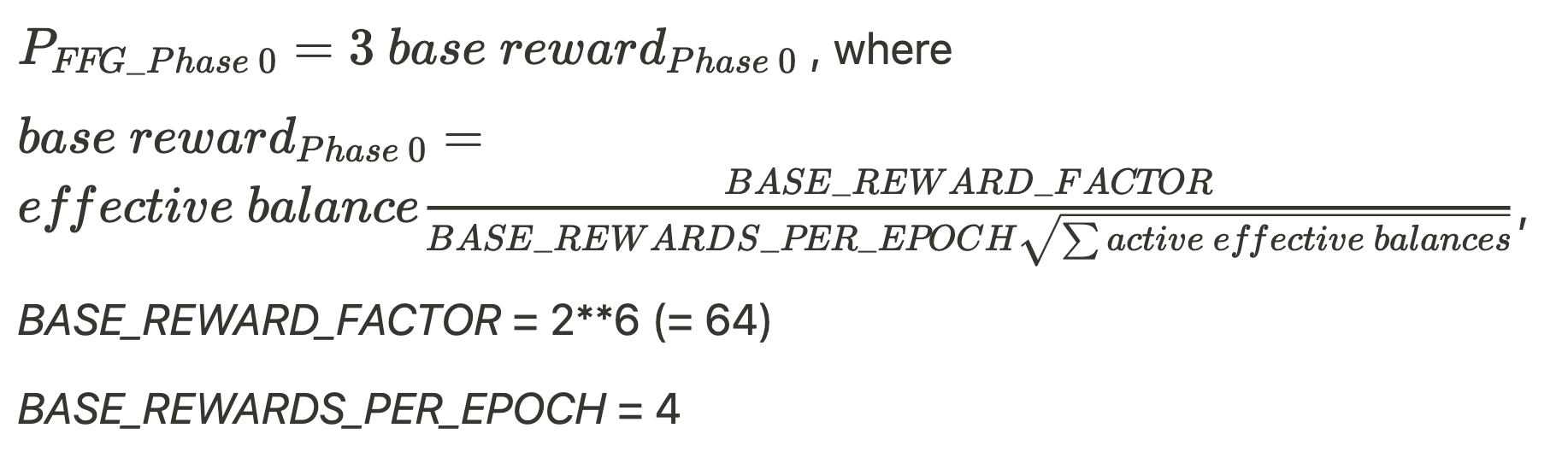
- Altair

- Phase 0
- For non-participation in the sync committee when assigned to one (Altair only)

Slashed Validator
Slashing" is the burning of some amount of validator funds and immediate ejection from the active validator set. In Phase 0, there are two ways in which funds can be slashed: proposer slashing and attester slashing. (Source)
A slashed validator is forced to exit with its balance penalized in each epoch during the period it is on the leaving queue. Being slashed brings 3 penalties:
- In the moment of slashing

- Special penalty on half-way exiting
- Phase 0

- Altair

- Phase 0
- FFG Penalty during the exit process for each epoch
- Phase 0
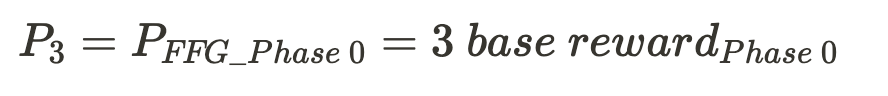
- Altair

- Phase 0
To wrap it up, the total amount of offline penalties depends on the number of offline validators, as well as on duration of being offline and whether a validator was assigned to the sync committee during offline state. The total losses could be reduced in case of timely reaction by the node operator(s).
On the contrary, the amount of slashing penalties depends only on the number of slashed validators and once the slashings have happened there is nothing one can do to reduce the losses.
Departing from these statements, the next section details the model used for our risk assessment.
Modelling Risk Events
Model Building Blocks
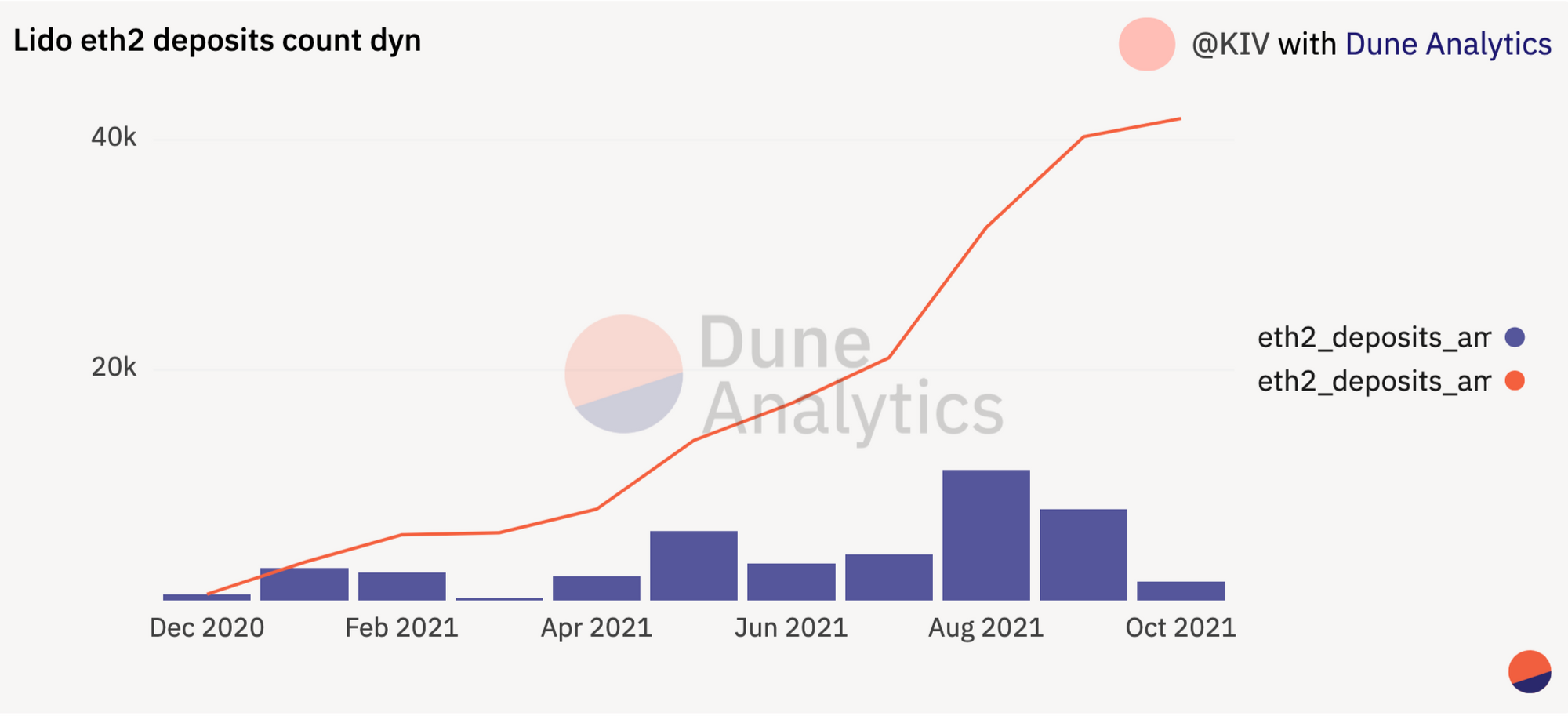
Currently, Lido is experiencing very rapid growth. In the last 2 months, Lido's deposits on the Beacon Chain have doubled.
Isolated instances of a small number of validators being offline and/or getting slashed are not of interest in terms of insurance, because the overall impact is very low.
The cases considered in this post include large amounts of validators going offline and/or being slashed. The realistic scenarios for such events include hardware damage, software malfunction, or global connectivity issues, as well as a compromised node operator, a malicious node operator, or a major mistake in node operations.
Basic Scenarios in the Model
The basic scenarios reflect the current and future Lido positions.
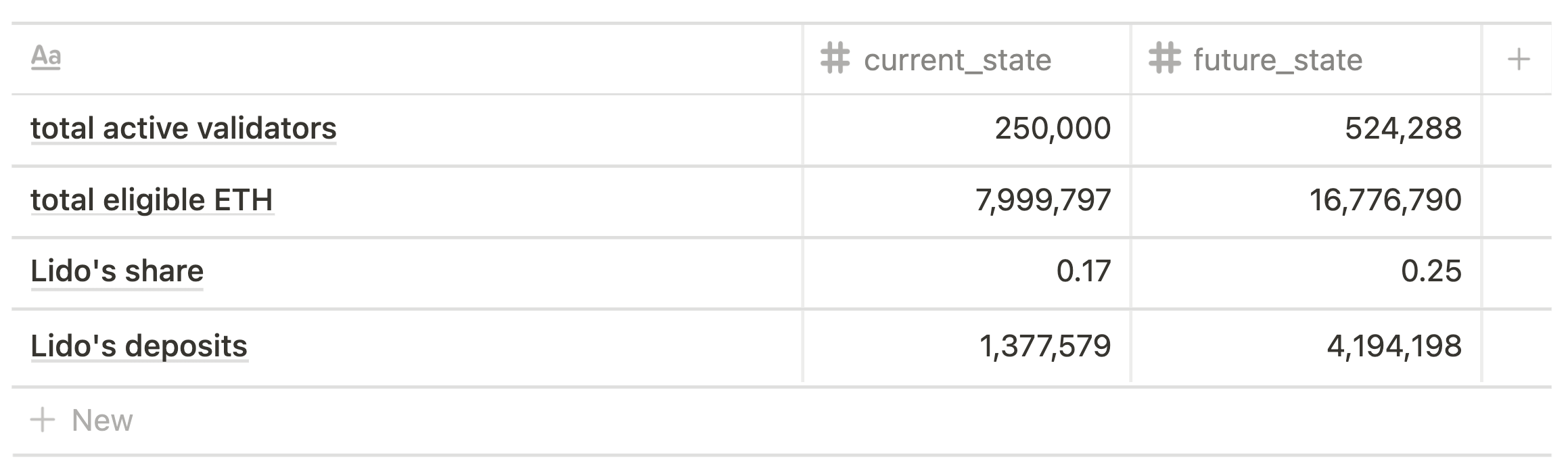
By 'current state' scenario we mean the Beacon Chain state and Lido's position at the moment of writing (October, 2021).
Currently, Lido has more than 1.3m Ether staked that equal ~17% of all Bacon Chain deposits, and the 4 largest node operators have 5,265 validators each.
For the 'current state' scenario we consider total active validators as 250,000 and, according to the current average effective balance, the total amount of eligible ETH as 7,999,797. Lido's deposits are calculated using its current market share.
The hypothetical 'future state' is modeled against the proposed maximum number of validators that be “awake” at any time, as proposed by Vitalik Buterin (~2 times more than current number), with Lido's share being 25%, and the 2 largest node operators having 10,000 validators each.
Basic scenarios
Risk Event Scale
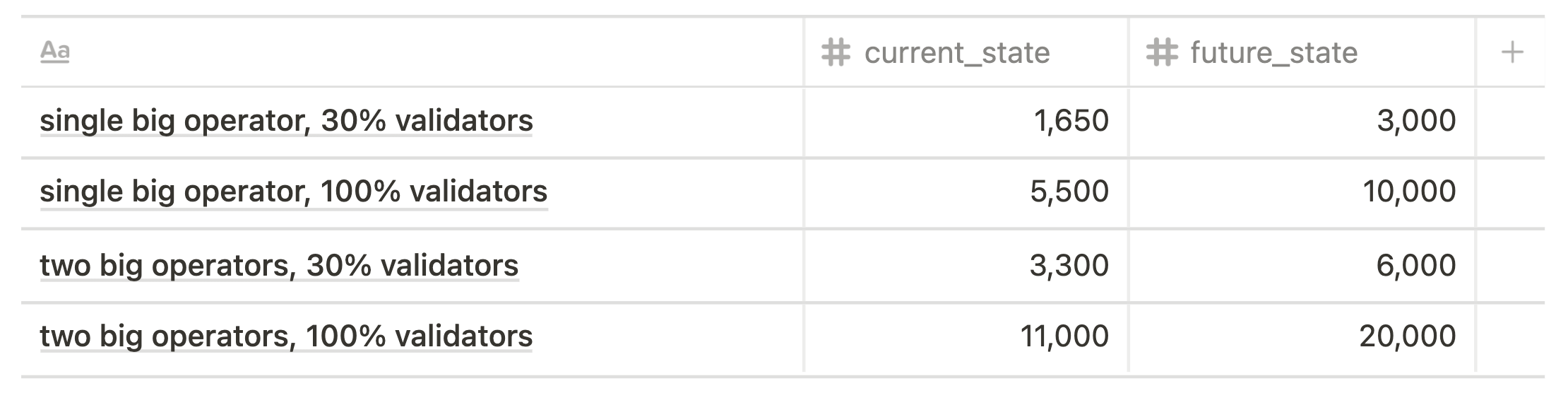
4 basic cases of large offline/slashing event (in terms of risk event scale) are taken into consideration:
- single biggest node operator, 30% validators
- single biggest node operator, 100% validators
- two biggest node operators, 30% validators (= single biggest node operator, 60%)
- two biggest node operators, 100% validators
Risk event scale: basic cases
Model Basic Assumptions
Basic assumptions that were made in the model:
- Beacon Chain does not go into the leak mode
- offline/slashed validators have equal balances and effective balances
- average effective balance and the number of active validators on the Beacon Chain do not change during the offline period (for offline validators) or withdrawals period (for slashed validators)
- Lido's slashed validators are the only slashed validators on the Beacon Chain
- The average effective balance of Lido's validators is 32 ETH, the average balance of Lido's validators is 33 ETH
- For comparison we used 5-year earnings at current rates: assuming a recent daily earning of 10.15 stETH, if we continue to earn this for 5 years we'll get 18,531 ETH
Offline penalty losses
Phase 0
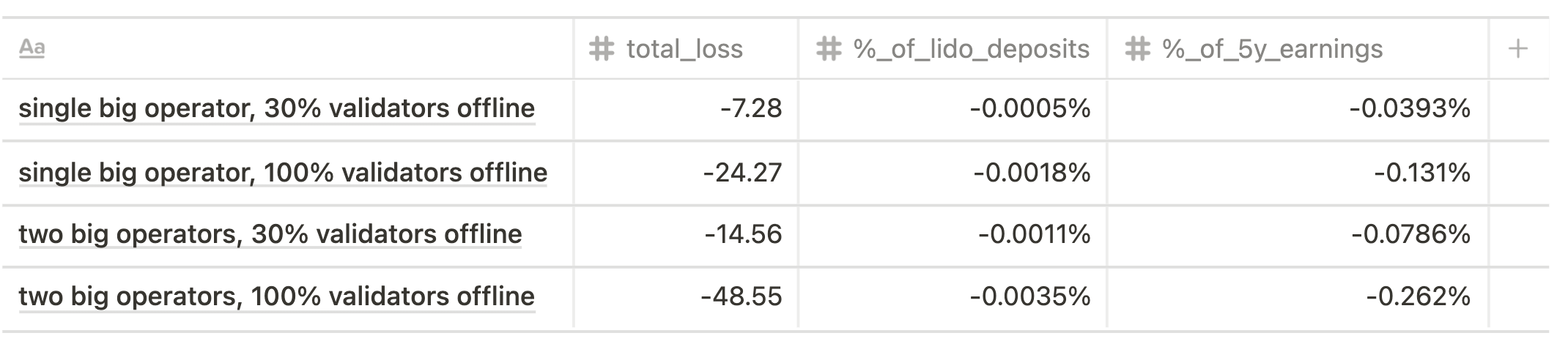
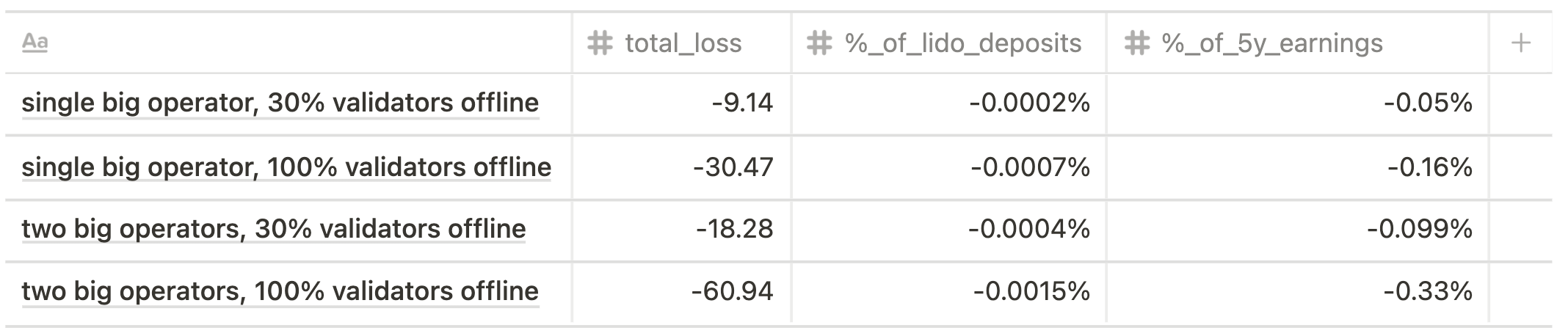
Phase 0 spec implies penalties for missing source-, target-, and head- vote (FFG penalty) that are imposed during each epoch of being offline.
We suggested that a non-malicious, non-compromised validator shouldn't go down for more than a day, so for the calculation we took the period of 256 epoch (~27 h).
The results are shown below.
Current state scenario
Future state scenario
Altair
In order to calculate all losses due to offline penalties according to the Altair spec, the number of validators chosen to the sync committee should be defined in addition to the duration of offline period.
Similar to Phase 0 spec, we assumed an offline period of 256 epochs. As for the other parameter, we need to understand the probability of being assigned to the committee of 512 validators.
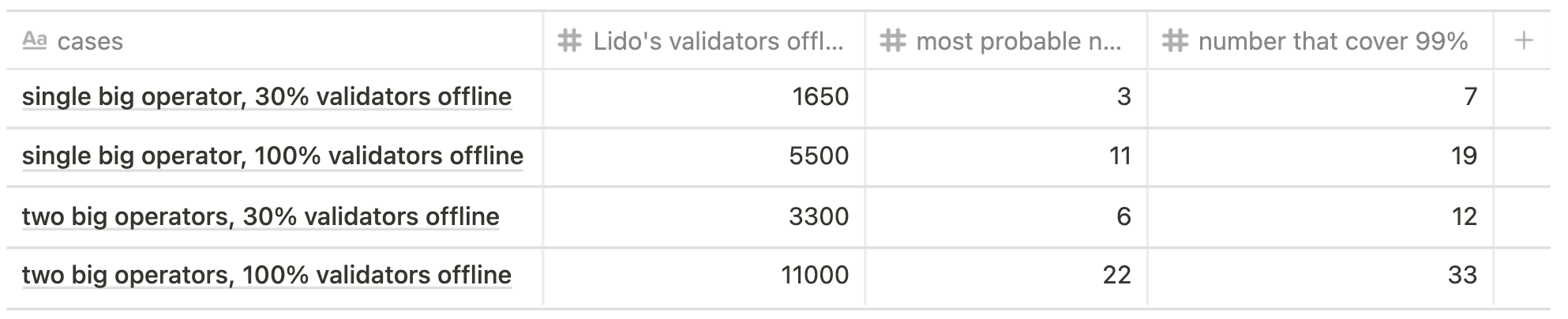
Obviously, the greater the number of offline validators is, the higher is the probability:

In the tables below one can see the most probable number of validators assigned to a committee and how many cases cover nearly 100% of all outcomes in relation to the total number of offline validators and chosen scenario.
Current state scenario
Future state scenario
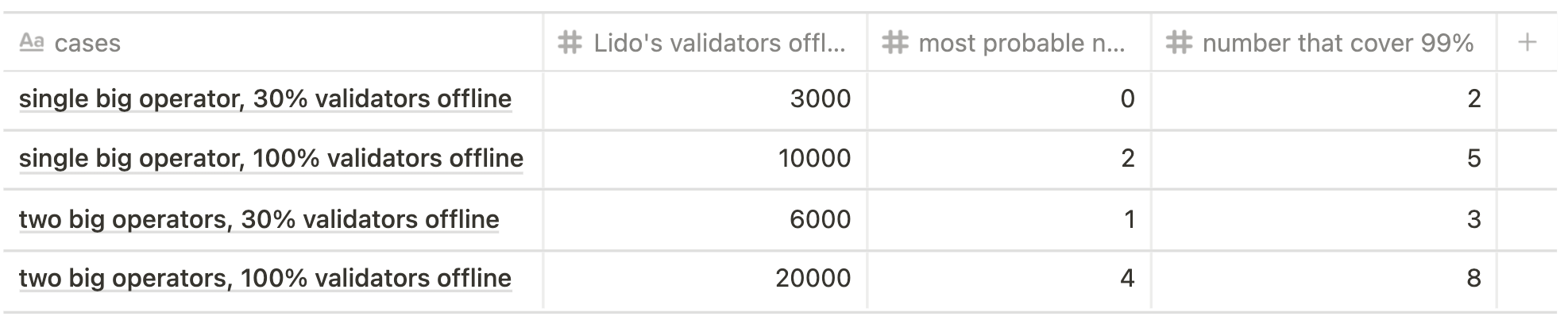
Let's illustrate this concept through the case of 5500 offline validators, current state scenario.
While validators are chosen to the sync committee randomly, the array of all possible outcomes is [0, 1, 2, ... 512] out of 5500 Lido's offline validators.
Using the formula above, the most probable number assigned to the sync committee would be 11 out of 5500 (probability ~12,6%) while the array [0, 1, 2, ... 19] out of 5500 would cover ~99% of probability. Realistically, this means that in the worst of cases we would face a the sync penalty of 19 validators (if we reduce the confidence interval to 90%, the number of validators will be 15).
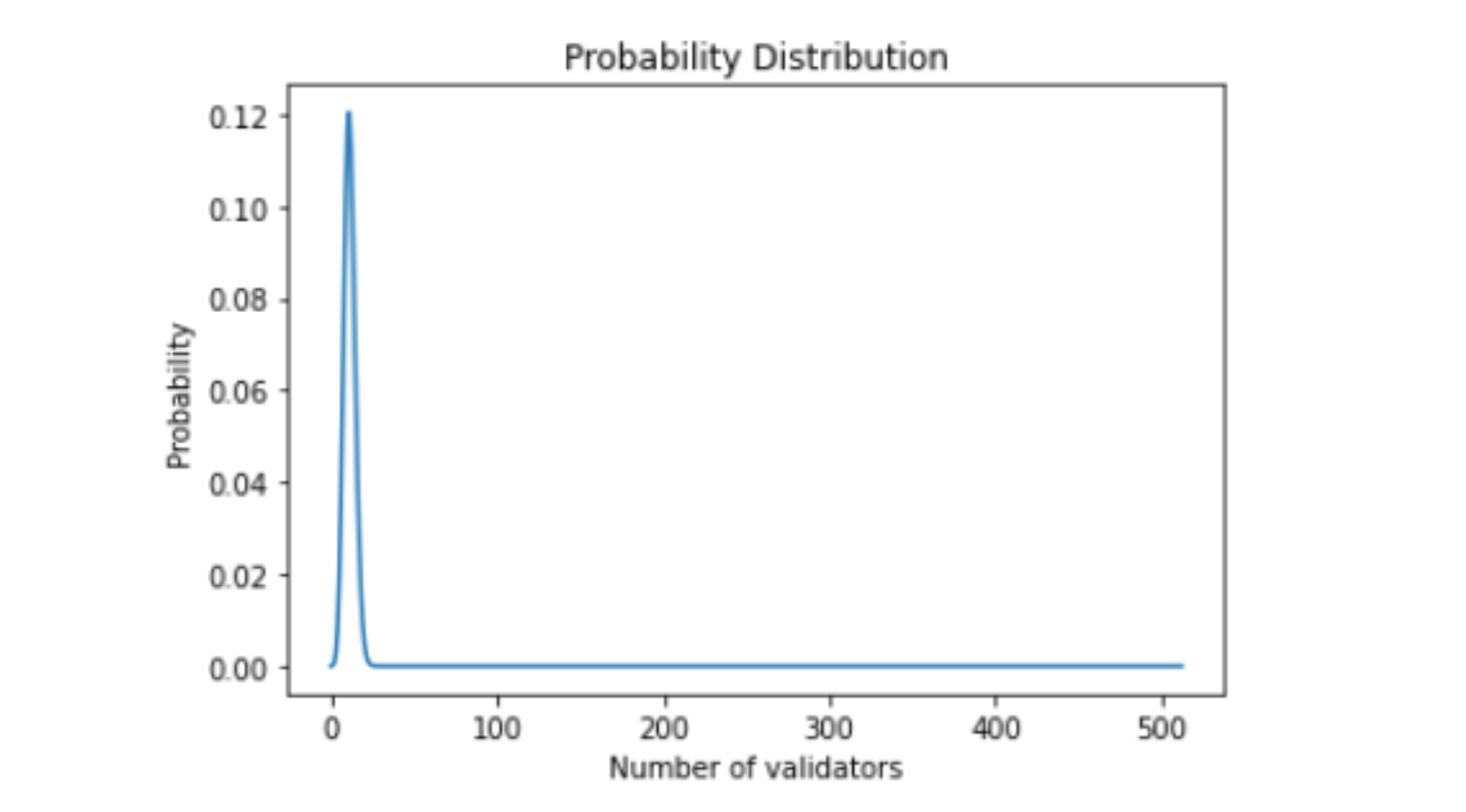
Thus, possible losses due to sync penalty were calculated on the basis of the max number of validators covering 99% of probability.
The offline penalties for Altair spec are shown below.
Current state scenario
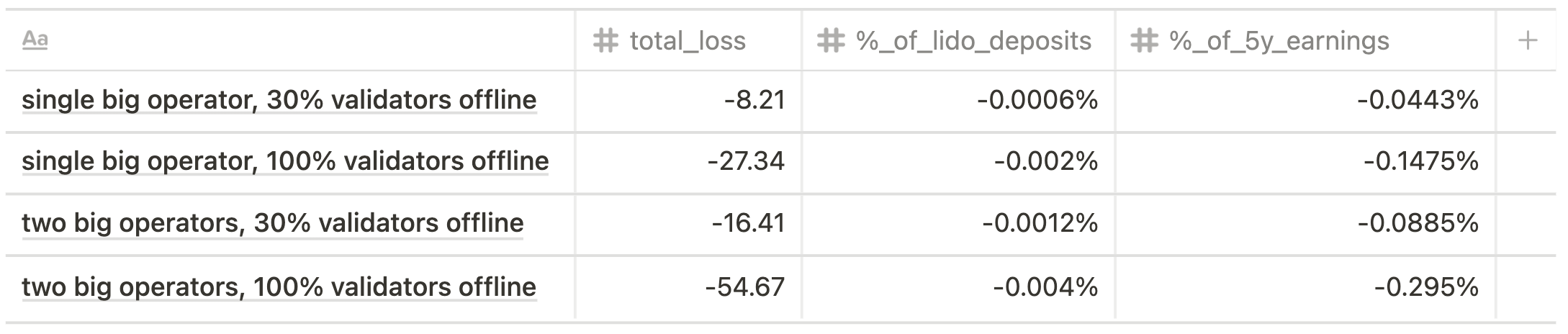
Future state scenario
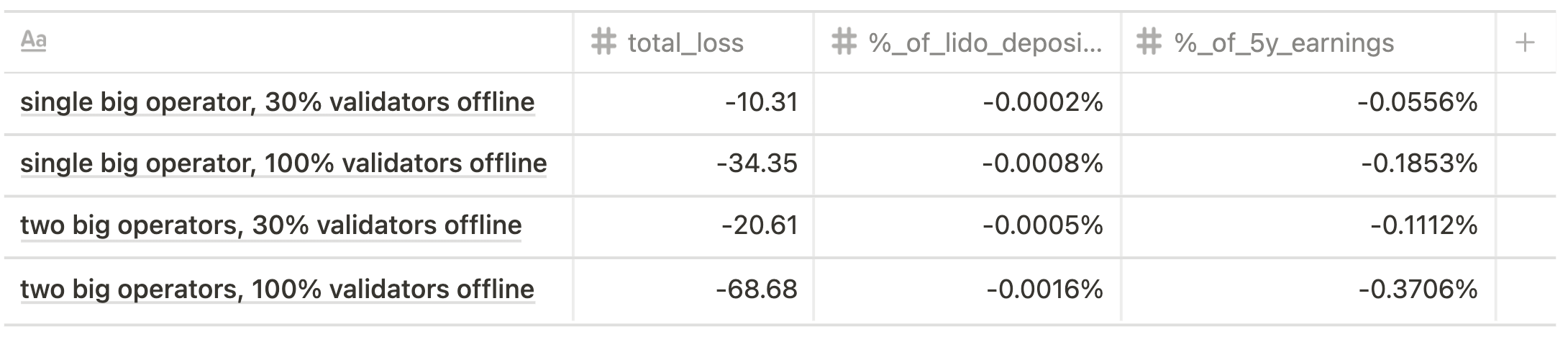
Slashing Penalty Losses
A validator will be slashed for (Source):
- signing two conflicting BeaconBlock, where conflicting is defined as two distinct blocks within the same slot
- signing two conflicting AttestationData objects, i.e. two attestations that satisfy
, which checks the double vote and surround vote conditions. - double vote: by a voting more than once for the same target epoch
- surround vote: the source–target interval of one attestation entirely contains the source–target of a second attestation from the same validator(s).
Although possible proposer slashings are capped at maximum of 16, a single attester slashing can be used to slash many misbehaving validators at the same time. Thus, it was assumed that the validators are all slashed in the same block.
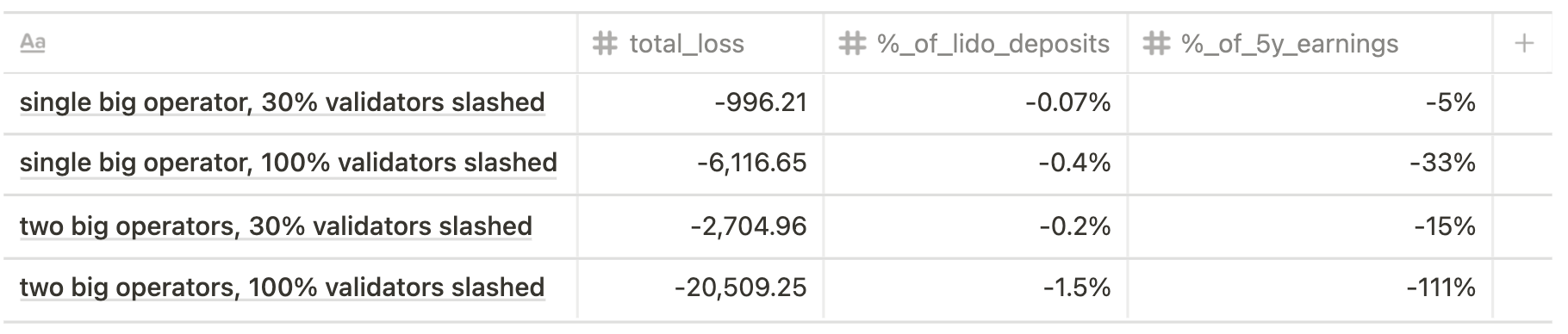
Phase 0
Current state scenario
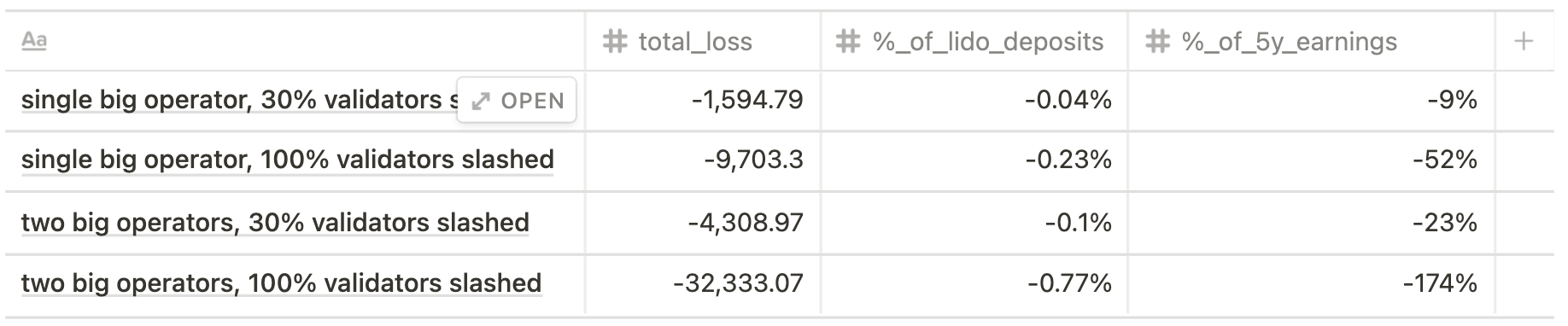
Future state scenario
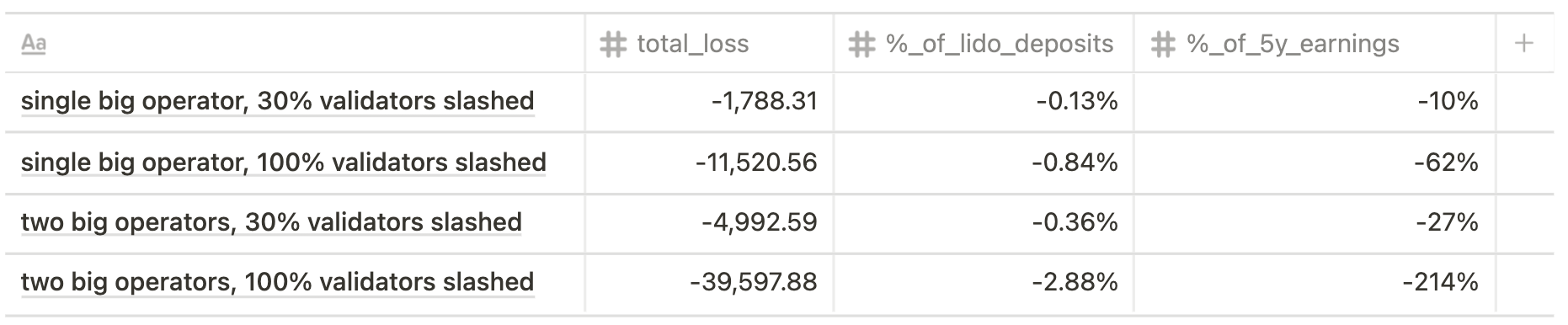
Altair
Current state scenario
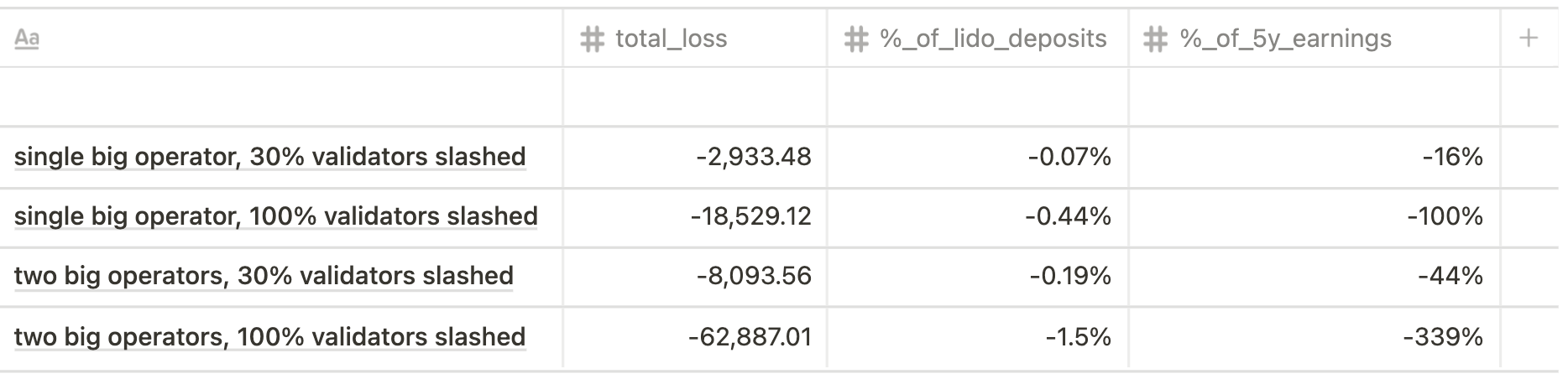
Model Python Code
You can access the full Python code used in our analysis here.
Risk Scenarios
Let's have a look at possible realistic situations that can lead (or have already led) to considered risk events. Again, for the offline penalties, we assess the scale (number of validators offline) and the duration (period of being offline), while for slashing penalties - only scale.
It would be appropriate to mention that, since the Beacon Chain has been launched, there have been only 150 slashings (17 for Proposer Violations and 133 for Attestation Violations).
Offline Validators
The chief reasons that our validators may go offline could be connected with hardware damage, software malfunction, or connectivity issues. It seems highly unlikely to get all three at the same time.
1. Hardware Risk (hardware damage)
Relevant example (datacenter fire): at 00:47 on Wednesday, March 10, 2021, a fire broke out in Strasbourg Datacenter. As a result SBG2 was totally destroyed, SBG1 and SBG3 damaged. SBG4 had no physical impact. There was no restart for SBG1, SBG3 and SBG4.
For this kind of risk event the scale and the duration depend on the extent to which validators are distributed. The other factor that determines the offline damage scope is a good disaster recovery plan.
For Lido node operators we assume the following:
- min scale/duration: 30% validators offline for 2 hours (well-distributed node operator, no issues with recovery)
- max scale/duration - 100% validators offline for 7 days (not-distributed node operator, issues with recovery)
Software Risk (client malfunction)
During two periods of 18 epochs each, nearly all Prysm validators were unable to produce new blocks on Friday, April 23, 2021, and on Saturday, April 24, 2021. This led to a decrease in validator participation and as a result to missed attestation penalties and an opportunity loss on proposal rewards.
During this period, over 70% of slots were empty. The case impact:
- Total loss ~ 25 ETH
- Per-validator loss ~ 205000 gwei
- 120 person hours in the 30 hours between detection and resolution
The scale and the duration of such events largely depend on client implementation (and types of client bugs) and how diversified clients are amongst validators and node operators, the latter being more essential. The problem arose due to a concentration of validators using solely the Prysm client. The impact would have been less heavy if there had been a better distribution of validator client implementations. Client diversity is the cornerstone here.
Currently we cannot specify min and max scale/duration for Lido node operators regarding this risk, as Lido's validator client distribution is in the progress of being assessed.
We assume the upper limit for a realistic impact as:
- Scale/duration - 100% validators offline for 7 day
Regulatory Risk (government takedown)
This risk refers to node operators falling under the scope of local or global regulators that could force validators to cease activities. Again, the scale and the duration depend on how validators/node operators are geographically distributed, and associated disaster recovery plans.
We assume that a week is enough to migrate validation to some friendly jurisdiction/location.
- scale/duration - 100% validators offline for 3 days
Loss Calculation
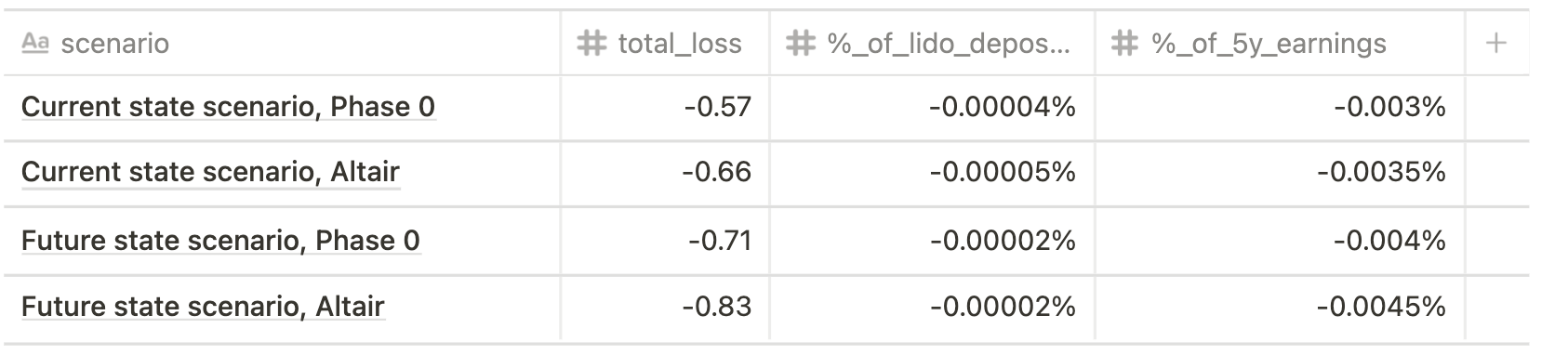
Min risk (single big operator, 30% validators offline for 2 hours)
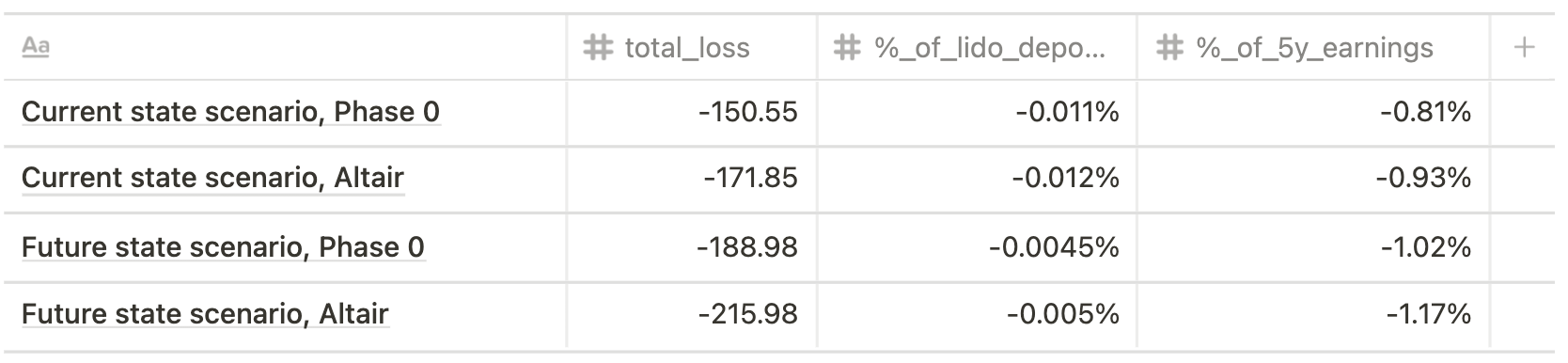
Max risk (single big operator, 100% validators offline for 7 days)
Large Slashing Event
A validator following the protocol in a correct manner would never intentionally attack the network and therefore get slashed. That said, a non-malicious slashable action can happen due to software or script bugs, operational accidents, or badly configured validation setups.
Accidental technical issue
A redundancy gone wrong: Staked case, Feb 3, 2021. (Source)
We attempted to scale up the number of beacon nodes to get better performance. While we had tested in our canary environment, the production load that we were trying to alleviate behaved differently, causing our validators to restart more frequently than we'd seen in testing. Because we had disabled the persistence of #1 above, these validators signed a second version of the same blocks: a major issue that led to a slashing event.
At the end, the case had very small impact:
- 75 Staked-run validators were slashed
- Total loss ~ 18 ETH
We assume that for this risk
- min scale: up to 300 validators slashed (bug or accident being spotted and fixed in several hours)
- max scale/duration - up to 30% validators slashed and 100% validators offline for 7 days (a redundancy gone wrong followed by taking all validators offline to understand and fix what happened)
Malicious or compromised node operator
A node operator can be a subject of hacker attack, can face total key loss or theft, leading to multiple malicious or compromised validators.
Assuming the max risk here:
- scale - up to 100% validators slashed
Losses calculation
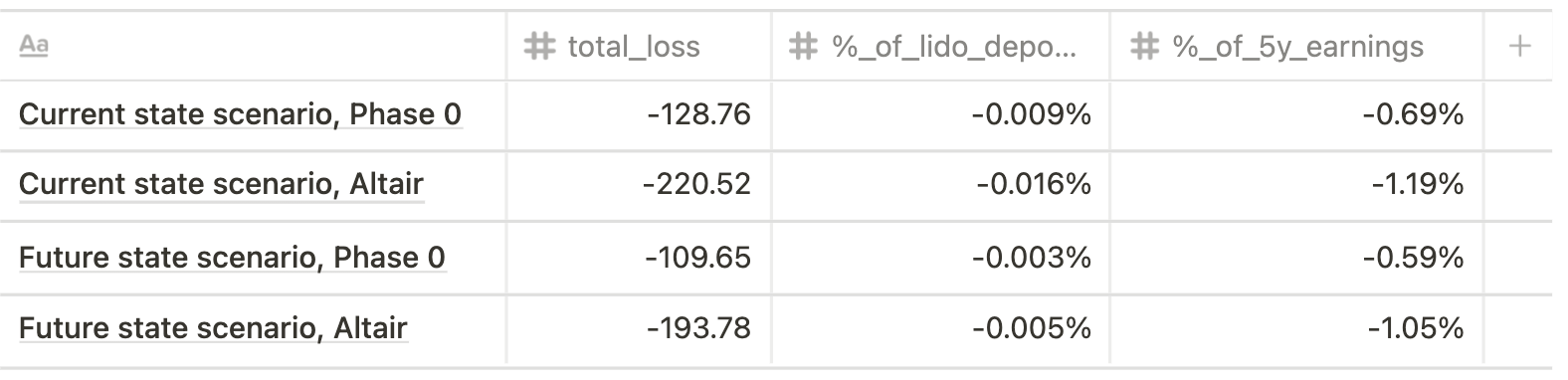
- Min impact (300 validators slashed)
- Medium impact (single big operator, 30% validators slashed, 100% validators offline for 7 days)

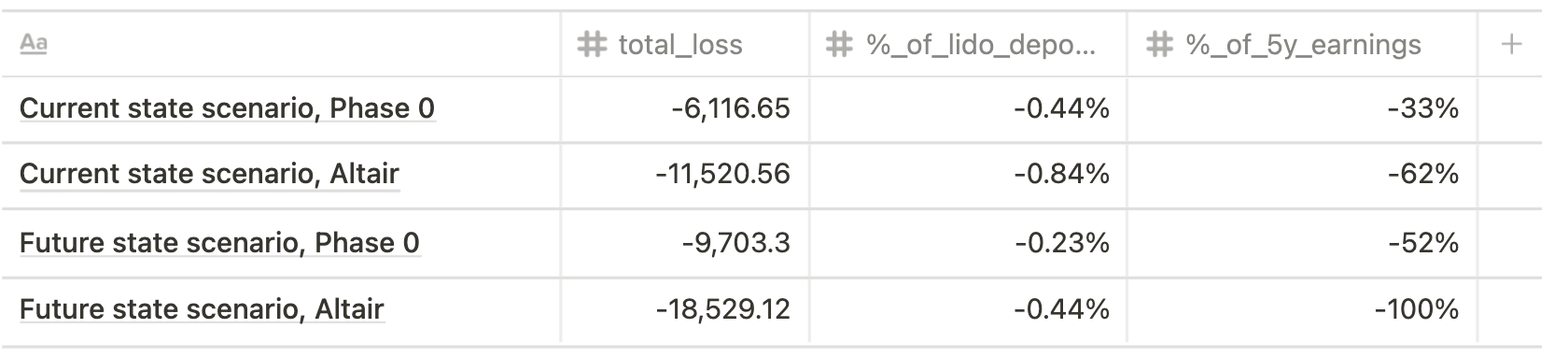
- Max risk (single big operator, 100% validators slashed)
Catastrophic Scenarios
We assume that a hypothetical catastrophic future event that could significantly damage node operator activities could be:
Accidental or intentional actions that cause “snowball effect” and end up with risk events presented above on a global scale, such as
- multiple malicious node operators
- full scale government takedown
The impact is proportional to the number of node operators hit by the event (multiple malicious node operators collusion) up to 100% loss of deposits (e.g. regulatory action shutting down all node operators).
Large offline & slashing event during "leak" mode
The Beacon Chain starts operating in "leak" mode if the last finalised epoch is longer than 4 epochs ago. Despite differences in the penalties calculation mechanism in Phase 0 and Altair, for fully inactive validators the impact is the same: non-participating validators receive an offline penalty that increases linearly with the number of epochs since finalisation. The Altair spec makes inactivity leaks more punitive than the Phase 0 spec.
If the Beacon Chain stopped finalising for ~ 18 days, fully inactive validators would lose from 11.8% (Phase 0) to 15.4% (Altair) of their balances.
For an offline validator the worst scenario is being sent to exit when its effective balance falls to 16 ETH. This would require either inactivity during a very serious leak (that lasts more than 36 days) or initially low validator's effective balance (that means the validator was systematically punished before).
For a slashed validator the worst scenario is being slashed right before a very serious leak that would drop its effective balance up to 60%.
Catastrophic events cannot be realistically self-covered. We take such catastrophic scenarios to be extremely unlikely.
Risk Mitigation
The total impact of risk events is largely determined by our preparedness regarding proactive measures and risk planning, as well as risk response in high-stress situations.
Self-cover
As we can see from the quick review of possible situations that could end up with losses, irrespective of source (offline penalties or large slashing event) and Beacon Chain spec (Phase 0 and Altair), total losses do not exceed 5 year Lido earnings at current rates.
Given that the third-party insurance policy covers any single node operator from no more than 5% slashing, the self-cover alternative seems to be a reasonable alternative.
The next steps here could be connected with further discussion on additional actions aimed to shape a financial model for self-insurance (initially discussed here).
A non-exhaustive list of mechanisms to reduce the risk for stakers could include:
- allocating part of the Lido's earnings to an internal Reserve Fund (some sort of special capital pool), possibly diversifying it into non-staked assets,
- implementing staking LDO for a portion of staking rewards as a risk-bearing buffer (LDO staked is slashed first),
- implementing staking stETH for a portion of staking rewards as a risk-bearing buffer, essentially implementing a risk tranching mechanism,
- allocating a part of the Lido treasury to internal Reserve Fund, and
- seeking additional (differently structured) 3rd party risk cover options.
Validator diversity
The key concept for risk reduction is diversification. In order to reduce validator risk, node operators and Lido in aggregate should distribute and diversify via:
- hardware: having within one node operator multiple on-premise and cloud solutions using different data centers and infrastructure providers,
- software: using within one node operator different client implementations, and
- meatspace distribution: being geographically distributed, with a preference for locations with stable and clear regulatory outlook.
The first step here will be a validator diversity assessment, in order to determine the scale and the probability of risk events Lido may face.
Commitment to highest professional standards
This part is more about risk planning. The most essential facets here would be:
- clear requirements and procedures for new node operator onboarding in order to keep the target level of node operators quality,
- procedures for node operator assessments and self-assessments,
- clear requirements and procedures for any validator performance improvements, and
- clear procedures for response in case of severe technical issues (e.g. Disaster Recovery Plan).
The possible first steps here seem to be as follows:
- to brainstorm criteria for node operator excellence,
- to develop a check-list for self-assessment (min required for steady validators performance),
- to identify (during brainstorming session) possible risk events and develop action plan for those that seem to be of high impact/probability.
Conclusion
For both Phase 0 and Altair specs of the Beacon Chain and projected Lido market share, the total losses of either extreme offline penalties or a large slashing event would not exceed 5 year Lido earnings at current rates.
The only case that would be not covered with 5 year Lido earnings at current rates is the situation of 20,000 validators slashed (2 big operators, Altair spec) that seems quite a tail risk.
The most probable severe outcomes could be:
- single not-distributed big operator, 100% validators offline for 7 days
- single big operator, 30% validators slashed, 100% validators offline for 7 days due to some client bugs or a redundancy gone wrong followed by taking all validators offline to understand and fix what happened
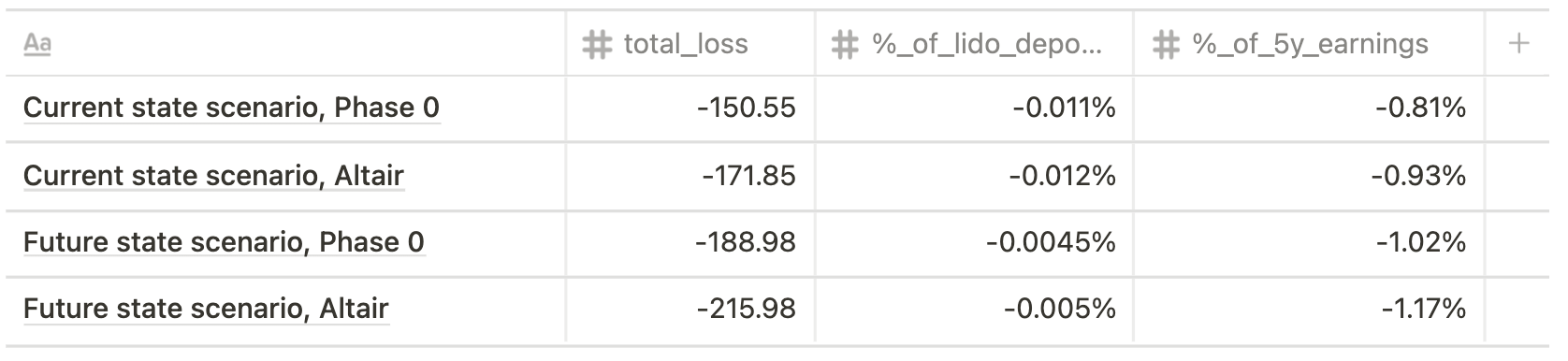
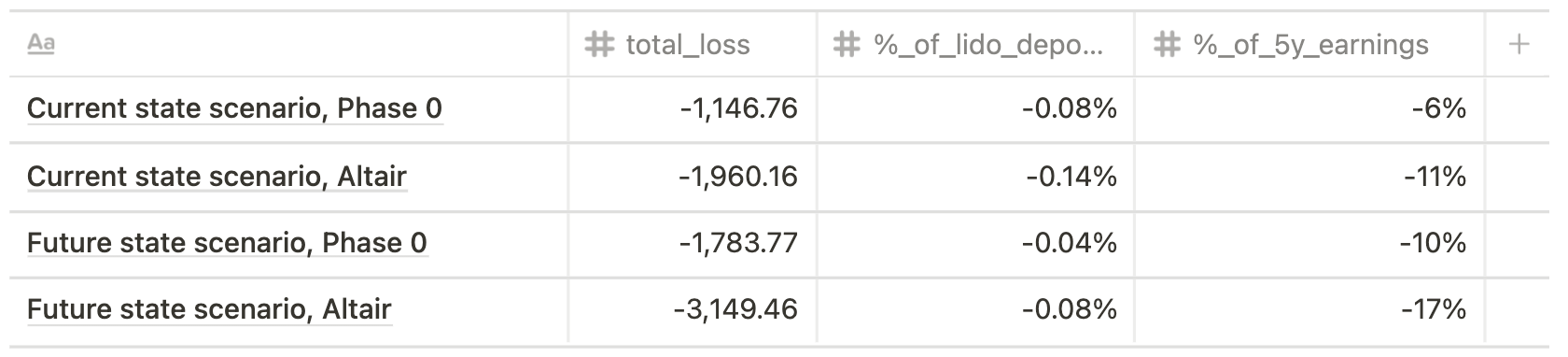
Assuming that currently a single big operator runs 5,000 validators (current state scenario) and future state scenario implies running 10,000 validators, the impact varies from 137 ETH to 216 ETH for the former outcome and from 1,013 ETH to 3,149 ETH for the latter.
Single not-distributed big operator, 100% validators offline for 7 days
Single big operator, 30% validators slashed, 100% validators offline for 7 days
Considering the third-party insurance policy that covers every single one node operator from no more than 5% slashing, the self-cover alternative would be the reasonable alternative.
Besides self-insurance, it seems meaningful to assess and manage validator diversity, develop risk & response planning, and cultivate commitment to the highest professional standards.
Acknowledgements
We would like to thank Vasiliy Shapovalov, Isidoros Passadis, Pintail, Eugene Pshenichniy, Victor Suzdalev, Hasu, and Elias Simos for their valuable comments and suggestions.